
HW4. Backpropagation
Topics: Backpropagation, Multi-layer perceptron
import pickle
import numpy as np
import matplotlib.pyplot as plt
import os
import math
from torchvision.datasets import CIFAR10
download = not os.path.isdir('cifar-10-batches-py')
dset_train = CIFAR10(root='.', download=download)
import torch
Problem 1: Understanding Backpropagation
1.(a) Implement the forward and backward pass 1
Implement the code for forward and backward pass for \(f(\overset {\rightarrow} {x}, \overset {\rightarrow} {w}) = \frac{1}{1 + exp(- (w_0x_0 + w_1x_1 - w_2/x_2 + w_3))}\)
def forward_helper(x0, x1, x2, w0, w1, w2, w3):
sum_part = -(w0 * x0 + w1 * x1 - w2/x2 + w3)
denum = 1 + np.exp(sum_part)
return 1 / denum
def f_1(x0, x1, x2, w0, w1, w2, w3):
"""
Computes the forward and backward pass through the computational graph
of (a)
Inputs:
- x0, x1, x2, w0, w1, w2, w3: Python floats
Returns a tuple of:
- L: The output of the graph
- grads: A tuple (grad_x0, grad_x1, grad_x2, grad_w0, grad_w1, grad_w2,
grad_w3)
giving the derivative of the output L with respect to each input.
"""
###########################################################################
# TODO: Implement the forward pass for the computational graph for (a) and#
# store the output of this graph as L #
###########################################################################
s0 = x0 * w0
s1 = x1 * w1
a = 1 / x2
s2 = a * w2
b = s0 + s1
c = b - s2
d = c + w3
e = -1 * d
f = np.exp(e)
g = f + 1
L = 1 / g
###########################################################################
# END OF YOUR CODE #
###########################################################################
###########################################################################
# TODO: Implement the backward pass for the computational graph for (a) #
# Store the gradients for each input #
###########################################################################
grad_L = 1
grad_g = -1 / (g**2)
grad_f = grad_g
grad_e = np.exp(e) * grad_f
grad_d = -1 * grad_e
grad_c = grad_d
grad_w3 = grad_d
grad_b = grad_c
grad_s2 = grad_c
grad_s0 = grad_b
grad_s1 = grad_b
grad_x0 = w0 * grad_s0
grad_w0 = x0 * grad_s0
grad_x1 = w1 * grad_s1
grad_w1 = x1 * grad_s1
grad_a = w2 * grad_s2
grad_w2 = a * grad_s2
grad_x2 = -1 / (x2**2) * grad_a
###########################################################################
# END OF YOUR CODE #
###########################################################################
grads = (grad_x0, grad_x1, grad_x2, grad_w0, grad_w1, grad_w2, grad_w3)
return L, grads
1.(b) Implement the forward and backward pass 2
Implement the code for forward and backward pass of the below computation graph.
.png)
def f_2(w, x, y, z):
"""
Computes the forward and backward pass through the computational graph
of (c)
Inputs:
- w, x, y, z: Python floats
Returns a tuple of:
- L: The output of the graph
- grads: A tuple (grad_w, grad_x, grad_y, grad_z)
giving the derivative of the output L with respect to each input.
"""
###########################################################################
# TODO: Implement the forward pass for the computational graph for (c) and#
# store the output of this graph as L #
###########################################################################
a = w**(-1)
b = -x
e = a**b
c = np.exp(y)
d = np.exp(z)
c1 = c
c2 = c
d1 = d
d2 = d
p = c1 * d1
p1 = p
p2 = p
f = c2 + p1
g = d2 / p2
m = e - f
n = m / g
L = n**2
###########################################################################
# END OF YOUR CODE #
###########################################################################
###########################################################################
# TODO: Implement the backward pass for the computational graph for (c) #
# Store the gradients for each input #
###########################################################################
grad_L = 1
grad_n = 2 * n * grad_L
grad_m = (1 / g) * grad_n
grad_g = (-m / g**2) * grad_n
grad_e = grad_m
grad_f = -grad_m
grad_a = b * (a**(b - 1)) * grad_e
grad_b = (a**b) * np.log(a) * grad_e
grad_w = (-1 / w**2) * grad_a
grad_x = -grad_b
grad_c2 = grad_f
grad_p1 = grad_f
grad_d2 = (1 / p2) * grad_g
grad_p2 = (-d / p2**2) * grad_g
grad_p = grad_p1 + grad_p2
grad_c1 = d1 * grad_p
grad_d1 = c1 * grad_p
grad_c = grad_c1 + grad_c2
grad_d = grad_d1 + grad_d2
grad_y = np.exp(y) * grad_c
grad_z = np.exp(z) * grad_d
###########################################################################
# END OF YOUR CODE #
###########################################################################
grads = (grad_w, grad_x, grad_y, grad_z)
return L, grads
Problem 2: Softmax Classifier with Two Layer Neural Network
In this problem you will develop a two Layer neural network with fully-connected layers to perform classification, and test it out on the CIFAR-10 dataset.
We train the network with a softmax loss function on the weight matrices. The network uses a ReLU nonlinearity after the first fully connected layer. In other words, the network has the following architecture:
input - fully connected layer - ReLU - fully connected layer - softmax
The outputs of the second fully-connected layer are the scores for each class.
You cannot use any deep learning libraries such as PyTorch in this part.
2.(a) Layers
In this problem, implement fully connected layer, relu and softmax. Filling in all TODOs in skeleton codes will be sufficient.
def fc_forward(X, W, b):
"""
Computes the forward pass for a fully-connected layer.
The input X has shape (N, Din) and contains a minibatch of N
examples, where each example x[i] has shape (Din,).
Inputs:
- X: A numpy array containing input data, of shape (N, Din)
- W: A numpy array of weights, of shape (Din, Dout)
- b: A numpy array of biases, of shape (Dout,)
Returns a tuple of:
- out: output, of shape (N, Dout)
- cache: (X, W, b)
"""
###########################################################################
# TODO: Implement the forward pass. Store the result in out. #
###########################################################################
out = np.matmul(X, W) + b
###########################################################################
# END OF YOUR CODE #
###########################################################################
cache = (X, W, b)
return out, cache
def fc_backward(dout, cache):
"""
Computes the backward pass for a fully_connected layer.
Inputs:
- dout: Upstream derivative, of shape (N, Dout)
- cache: returned by your forward function. Tuple of:
- X: Input data, of shape (N, Din)
- W: Weights, of shape (Din, Dout)
- b: Biases, of shape (Dout,)
Returns a tuple of:
- dX: Gradient with respect to X, of shape (N, Din)
- dW: Gradient with respect to W, of shape (Din, Dout)
- db: Gradient with respect to b, of shape (Dout,)
"""
X, W, b = cache
dX, dW, db = None, None, None
###########################################################################
# TODO: Implement the affine backward pass. #
###########################################################################
dX = np.matmul(dout, np.transpose(W))
dW = np.matmul(np.transpose(X), dout)
db = np.sum(dout, axis = 0)
###########################################################################
# END OF YOUR CODE #
###########################################################################
return dX, dW, db
def relu_forward(x):
"""
Computes the forward pass for a layer of rectified linear units (ReLUs).
Input:
- x: Inputs, of any shape
Returns a tuple of:
- out: Output, of the same shape as x
- cache: x
"""
out = x.copy()
###########################################################################
# TODO: Implement the ReLU forward pass. #
###########################################################################
out[out < 0] = 0
###########################################################################
# END OF YOUR CODE #
###########################################################################
cache = x
return out, cache
def relu_backward(dout, cache):
"""
Computes the backward pass for a layer of rectified linear units (ReLUs).
Input:
- dout: Upstream derivatives, of any shape
- cache: returned by your forward function. Input x, of same shape as dout
Returns:
- dx: Gradient with respect to x
"""
dx, x = dout.copy(), cache
###########################################################################
# TODO: Implement the ReLU backward pass. #
###########################################################################
dx[x < 0] = 0
###########################################################################
# END OF YOUR CODE #
###########################################################################
return dx
def softmax_loss(X, y):
"""
Computes the loss and gradient for softmax classification.
Inputs:
- X: Input data, of shape (N, C) where x[i, j] is the score for the jth
class for the ith input.
- y: Vector of labels, of shape (N,) where y[i] is the label for X[i] and
0 <= y[i] < C
Returns a tuple of:
- loss: Scalar giving the loss
- dX: Gradient of the loss with respect to x
"""
loss, dX = None, None
dX = np.exp(X - np.max(X, axis=1, keepdims=True))
dX /= np.sum(dX, axis=1, keepdims=True)
loss = -np.sum(np.log(dX[np.arange(X.shape[0]), y])) / X.shape[0]
dX[np.arange(X.shape[0]), y] -= 1
dX /= X.shape[0]
return loss, dX
2.(b) Two Layer Softmax Classifier
In this problem, implement two layer softmax classifier.
class SoftmaxClassifier(object):
"""
A fully-connected neural network with
softmax loss that uses a modular layer design. We assume an input dimension
of D, a hidden dimension of H, and perform classification over C classes.
The architecture should be fc - relu - fc - softmax with one hidden layer
The learnable parameters of the model are stored in the dictionary
self.params that maps parameter names to numpy arrays.
"""
def __init__(self, input_dim=3072, hidden_dim=300, num_classes=10,
weight_scale=1e-3, reg=0.0):
"""
Initialize a new network.
Inputs:f
- input_dim: An integer giving the size of the input
- hidden_dim: An integer giving the size of the hidden layer, None
if there's no hidden layer.
- num_classes: An integer giving the number of classes to classify
- weight_scale: Scalar giving the standard deviation for random
initialization of the weights.
"""
self.params = {}
self.reg = reg
############################################################################
# TODO: Initialize the weights and biases of the two-layer net. Weights #
# should be initialized from a Gaussian centered at 0.0 with #
# standard deviation equal to weight_scale, and biases should be #
# initialized to zero. All weights and biases should be stored in the #
# dictionary self.params, with fc weights and biases using the keys #
# 'W' and 'b', i.e., W1, b1 for the weights and bias in the first linear #
# layer, W2, b2 for the weights and bias in the second linear layer. #
############################################################################
W1 = np.random.normal(0.0, weight_scale, (input_dim, hidden_dim))
b1 = np.zeros((hidden_dim,))
W2 = np.random.normal(0.0, weight_scale, (hidden_dim, num_classes))
b2 = np.zeros((num_classes,))
self.params["W1"] = W1
self.params["b1"] = b1
self.params["W2"] = W2
self.params["b2"] = b2
############################################################################
# END OF YOUR CODE #
############################################################################
def forwards_backwards(self, X, y=None):
"""
Compute loss and gradient for a minibatch of data.
Inputs:
- X: Array of input data of shape (N, Din)
- y: Array of labels, of shape (N,). y[i] gives the label for X[i].
Returns:
If y is None, then run a test-time forward pass of the model and return:
- scores: Array of shape (N, C) giving classification scores, where
scores[i, c] is the classification score for X[i] and class c.
If y is not None, then run a training-time forward and backward pass. And
return a tuple of:
- loss: Scalar value giving the loss
- grads: Dictionary with the same keys as self.params, mapping parameter
names to gradients of the loss with respect to those parameters.
"""
scores = None
############################################################################
# TODO: Implement the forward pass for the two-layer net, computing the #
# class scores for X and storing them in the scores variable. #
############################################################################
W1 = self.params["W1"]
b1 = self.params["b1"]
W2 = self.params["W2"]
b2 = self.params["b2"]
a_1, cache_fc1 = fc_forward(X, W1, b1)
s_1, cache_relu = relu_forward(a_1)
scores, cache_fc2 = fc_forward(s_1, W2, b2)
############################################################################
# END OF YOUR CODE #
############################################################################
# If y is None then we are in test mode so just return scores
if y is None:
return scores
loss, grads = 0, {}
############################################################################
# TODO: Implement the backward pass for the two-layer net. Store the loss #
# in the loss variable and gradients in the grads dictionary. Compute data #
# loss using softmax, and make sure that grads[k] holds the gradients for #
# self.params[k]. #
############################################################################
loss, grad_L = softmax_loss(scores, y)
ds_1, dW2, db2 = fc_backward(grad_L, cache_fc2)
da_1 = relu_backward(ds_1, cache_relu)
_, dW1, db1 = fc_backward(da_1, cache_fc1)
grads["W1"] = dW1
grads["b1"] = db1
grads["W2"] = dW2
grads["b2"] = db2
############################################################################
# END OF YOUR CODE #
############################################################################
############################################################################
# TODO: 4.2(g)(EECS 504 only) Add L2 regularization #
############################################################################
loss += self.reg * (np.sum(dW1 ** 2) + np.sum(dW2 ** 2))
############################################################################
# END OF YOUR CODE #
############################################################################
return loss, grads
2.(c) Training
In this problem, you need to preprocess the images and set up model hyperparameters. Notice that adjust the training and val split is optional.
def unpickle(file):
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding="latin1")
return dict
def load_cifar10():
data = {}
meta = unpickle("cifar-10-batches-py/batches.meta")
batch1 = unpickle("cifar-10-batches-py/data_batch_1")
batch2 = unpickle("cifar-10-batches-py/data_batch_2")
batch3 = unpickle("cifar-10-batches-py/data_batch_3")
batch4 = unpickle("cifar-10-batches-py/data_batch_4")
batch5 = unpickle("cifar-10-batches-py/data_batch_5")
test_batch = unpickle("cifar-10-batches-py/test_batch")
X_train = np.vstack((batch1['data'], batch2['data'], batch3['data'],\
batch4['data'], batch5['data']))
Y_train = np.array(batch1['labels'] + batch2['labels'] + batch3['labels'] +
batch4['labels'] + batch5['labels'])
X_test = test_batch['data']
Y_test = test_batch['labels']
#Preprocess images here
X_train = (X_train-np.mean(X_train,axis=1,keepdims=True))/np.std(X_train,axis=1,keepdims=True)
X_test = (X_test-np.mean(X_test,axis=1,keepdims=True))/np.std(X_test,axis=1,keepdims=True)
data['X_train'] = X_train[:40000]
data['y_train'] = Y_train[:40000]
data['X_val'] = X_train[40000:]
data['y_val'] = Y_train[40000:]
data['X_test'] = X_test
data['y_test'] = Y_test
return data
def testNetwork(model, X, y, num_samples=None, batch_size=100):
"""
Check accuracy of the model on the provided data.
Inputs:
- model: Image classifier
- X: Array of data, of shape (N, d_1, ..., d_k)
- y: Array of labels, of shape (N,)
- num_samples: If not None, subsample the data and only test the model
on num_samples datapoints.
- batch_size: Split X and y into batches of this size to avoid using
too much memory.
Returns:
- acc: Scalar giving the fraction of instances that were correctly
classified by the model.
"""
# Subsample the data
N = X.shape[0]
if num_samples is not None and N > num_samples:
mask = np.random.choice(N, num_samples)
N = num_samples
X = X[mask]
y = y[mask]
# Compute predictions in batches
num_batches = N // batch_size
if N % batch_size != 0:
num_batches += 1
y_pred = []
for i in range(num_batches):
start = i * batch_size
end = (i + 1) * batch_size
scores = model.forwards_backwards(X[start:end])
y_pred.append(np.argmax(scores, axis=1))
y_pred = np.hstack(y_pred)
acc = np.mean(y_pred == y)
return acc
def SGD(W,dW, learning_rate=1e-3):
""" Apply a gradient descent step on weight W
Inputs:
W : Weight matrix
dW : gradient of weight, same shape as W
learning_rate : Learning rate. Defaults to 1e-3.
Returns:
new_W: Updated weight matrix
"""
# Apply a gradient descent step on weight W using the gradient dW and the specified learning rate.
new_W = W - learning_rate * dW
return new_W
def trainNetwork(model, data, **kwargs):
"""
Required arguments:
- model: Image classifier
- data: A dictionary of training and validation data containing:
'X_train': Array, shape (N_train, d_1, ..., d_k) of training images
'X_val': Array, shape (N_val, d_1, ..., d_k) of validation images
'y_train': Array, shape (N_train,) of labels for training images
'y_val': Array, shape (N_val,) of labels for validation images
Optional arguments:
- learning_rate: A scalar for initial learning rate.
- lr_decay: A scalar for learning rate decay; after each epoch the
learning rate is multiplied by this value.
- batch_size: Size of minibatches used to compute loss and gradient
during training.
- num_epochs: The number of epochs to run for during training.
- print_every: Integer; training losses will be printed every
print_every iterations.
- verbose: Boolean; if set to false then no output will be printed
during training.
- num_train_samples: Number of training samples used to check training
accuracy; default is 1000; set to None to use entire training set.
- num_val_samples: Number of validation samples to use to check val
accuracy; default is None, which uses the entire validation set.
- optimizer: Choice of using either 'SGD' or 'SGD_Momentum' for updating weights; default is SGD.
"""
learning_rate = kwargs.pop('learning_rate', 1e-3)
lr_decay = kwargs.pop('lr_decay', 1.0)
batch_size = kwargs.pop('batch_size', 100)
num_epochs = kwargs.pop('num_epochs', 10)
num_train_samples = kwargs.pop('num_train_samples', 1000)
num_val_samples = kwargs.pop('num_val_samples', None)
print_every = kwargs.pop('print_every', 10)
verbose = kwargs.pop('verbose', True)
optimizer = kwargs.pop('optimizer', 'SGD')
epoch = 0
best_val_acc = 0
best_params = {}
loss_history = []
train_acc_history = []
val_acc_history = []
num_train = data['X_train'].shape[0]
iterations_per_epoch = max(num_train // batch_size, 1)
num_iterations = num_epochs * iterations_per_epoch
#Initialize velocity dictionary if optimizer is SGD_Momentum
if optimizer == 'SGD_Momentum':
velocity_dict = {p:np.zeros(w.shape) for p,w in model.params.items()}
for t in range(num_iterations):
# Make a minibatch of training data
batch_mask = np.random.choice(num_train, batch_size)
X_batch = data['X_train'][batch_mask]
y_batch = data['y_train'][batch_mask]
# Compute loss and gradient
loss, grads = model.forwards_backwards(X_batch, y_batch)
loss_history.append(loss)
# Perform a parameter update
if optimizer == 'SGD':
for p, w in model.params.items():
model.params[p] = SGD(w,grads[p], learning_rate=learning_rate)
elif optimizer == 'SGD_Momentum':
for p, w in model.params.items():
model.params[p], velocity_dict[p] = SGD_Momentum(w, grads[p], velocity_dict[p], beta=0.5, learning_rate=learning_rate)
else:
raise NotImplementedError
# Print training loss
if verbose and t % print_every == 0:
print('(Iteration %d / %d) loss: %f' % (
t + 1, num_iterations, loss_history[-1]))
# At the end of every epoch, increment the epoch counter and decay
# the learning rate.
epoch_end = (t + 1) % iterations_per_epoch == 0
if epoch_end:
epoch += 1
learning_rate *= lr_decay
# Check train and val accuracy on the first iteration, the last
# iteration, and at the end of each epoch.
first_it = (t == 0)
last_it = (t == num_iterations - 1)
if first_it or last_it or epoch_end:
train_acc = testNetwork(model, data['X_train'], data['y_train'],
num_samples= num_train_samples)
val_acc = testNetwork(model, data['X_val'], data['y_val'],
num_samples=num_val_samples)
train_acc_history.append(train_acc)
val_acc_history.append(val_acc)
if verbose:
print('(Epoch %d / %d) train acc: %f; val_acc: %f' % (
epoch, num_epochs, train_acc, val_acc))
# Keep track of the best model
if val_acc > best_val_acc:
best_val_acc = val_acc
best_params = {}
for k, v in model.params.items():
best_params[k] = v.copy()
model.params = best_params
return model, train_acc_history, val_acc_history
# load data
data = load_cifar10()
train_data = { k: data[k] for k in ['X_train', 'y_train',
'X_val', 'y_val']}
# initialize model
model_SGD = SoftmaxClassifier(hidden_dim = 300, weight_scale=1e-2)
#######################################################################
# TODO: Set up model hyperparameters for SGD #
#######################################################################
# set the hyperparameter
learning_rate_SGD = 0.05
lr_decay_SGD = 0.15
batch_size_SGD = 100
# start training using SGD
model_SGD, train_acc_history_SGD, val_acc_history_SGD = trainNetwork(
model_SGD, train_data,
learning_rate = learning_rate_SGD,
lr_decay=lr_decay_SGD,
batch_size=batch_size_SGD,
num_epochs=10,
print_every=1000, optimizer = 'SGD')
#######################################################################
# END OF YOUR CODE #
#######################################################################
(Iteration 1 / 4000) loss: 2.310917
(Epoch 0 / 10) train acc: 0.156000; val_acc: 0.159400
(Epoch 1 / 10) train acc: 0.445000; val_acc: 0.435200
(Epoch 2 / 10) train acc: 0.494000; val_acc: 0.465600
(Iteration 1001 / 4000) loss: 1.344627
(Epoch 3 / 10) train acc: 0.519000; val_acc: 0.471000
(Epoch 4 / 10) train acc: 0.516000; val_acc: 0.471600
(Epoch 5 / 10) train acc: 0.512000; val_acc: 0.471800
(Iteration 2001 / 4000) loss: 1.488484
(Epoch 6 / 10) train acc: 0.516000; val_acc: 0.471900
(Epoch 7 / 10) train acc: 0.515000; val_acc: 0.471900
(Iteration 3001 / 4000) loss: 1.341380
(Epoch 8 / 10) train acc: 0.497000; val_acc: 0.471900
(Epoch 9 / 10) train acc: 0.502000; val_acc: 0.471900
(Epoch 10 / 10) train acc: 0.519000; val_acc: 0.471900
2.(d) Training with SGD_Momentum
The model above was trained using SGD. Now implement the SGD with momentum
def SGD_Momentum(W, dW, velocity, beta=0.5, learning_rate=1e-3):
""" Apply a gradient descent with momentum update on weight W
Inputs:
W : Weight matrix
dW : gradient of weight, same shape as W
velocity : velocity matrix, same shape as W
beta : scalar value in range [0,1] weighting the velocity matrix. Setting it to 0 should make SGD_Momentum same as SGD.
Defaults to 0.5.
learning_rate : Learning rate. Defaults to 1e-3.
Returns:
new_W: Updated weight matrix
new_velocity: Updated velocity matrix
"""
#######################################################################
# TODO: Apply a gradient descent step on weight W using the gradient dW and the specified learning rate.
# 1. Calculate the new velocity by using the velocity of last iteration (input velocity) and gradient
# 2. Update the weights using the new_velocity
#######################################################################
new_velocity = beta * velocity + learning_rate * dW
new_W = W - new_velocity
#######################################################################
# END OF YOUR CODE #
#######################################################################
return new_W, new_velocity
# initialize model
model_SGD_Momentum = SoftmaxClassifier(hidden_dim = 300, weight_scale=1e-2)
# start training
#Using SGD_Momentum as optimizer for trainning for training
model_SGD_Momentum, train_acc_history_SGD_Momentum, val_acc_history_SGD_Momentum = trainNetwork(
model_SGD_Momentum, train_data,
learning_rate = learning_rate_SGD,
lr_decay=lr_decay_SGD,
batch_size=batch_size_SGD,
num_epochs=10,
print_every=1000, optimizer = 'SGD_Momentum')
(Iteration 1 / 4000) loss: 2.297836
(Epoch 0 / 10) train acc: 0.174000; val_acc: 0.158800
(Epoch 1 / 10) train acc: 0.524000; val_acc: 0.454200
(Epoch 2 / 10) train acc: 0.573000; val_acc: 0.493500
(Iteration 1001 / 4000) loss: 1.495447
(Epoch 3 / 10) train acc: 0.549000; val_acc: 0.500900
(Epoch 4 / 10) train acc: 0.579000; val_acc: 0.501700
(Epoch 5 / 10) train acc: 0.579000; val_acc: 0.502400
(Iteration 2001 / 4000) loss: 1.325367
(Epoch 6 / 10) train acc: 0.584000; val_acc: 0.502600
(Epoch 7 / 10) train acc: 0.562000; val_acc: 0.502600
(Iteration 3001 / 4000) loss: 1.322262
(Epoch 8 / 10) train acc: 0.563000; val_acc: 0.502600
(Epoch 9 / 10) train acc: 0.580000; val_acc: 0.502600
(Epoch 10 / 10) train acc: 0.586000; val_acc: 0.502600
2.(e) Report Accuracy
Run the given code and report the accuracy of model_SGD and model_SGD_Momentum on test set.
# report test accuracy
acc = testNetwork(model_SGD, data['X_test'], data['y_test'])
print("Test accuracy of model_SGD: {}".format(acc))
# report test accuracy
acc = testNetwork(model_SGD_Momentum, data['X_test'], data['y_test'])
print("Test accuracy of model_SGD_Momentum: {}".format(acc))
Test accuracy of model_SGD: 0.4775
Test accuracy of model_SGD_Momentum: 0.4987
2.(f) Plot
Using the train_acc_history and val_acc_history, plot the train & val accuracy versus epochs on one plot, using SGD and SGD_Momentum as optimizer.
#######################################################################
# Your Code here
#######################################################################
plt.plot(train_acc_history_SGD, label = "train accuracy using SGD")
plt.plot(val_acc_history_SGD, label = "validate accuracy using SGD")
plt.plot(train_acc_history_SGD_Momentum, label = "train accuracy using SGD Momentum")
plt.plot(val_acc_history_SGD_Momentum, label = "validate accuracy using SGD Momentum")
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.legend()
plt.plot()
#######################################################################
# END OF YOUR CODE #
#######################################################################
[]
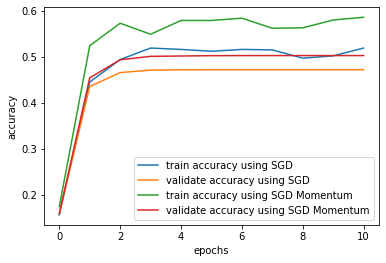
Report your obervation here: The model with SGD momentum optimizer trains quickly than the model with SGD. Train accuracy with SGD momentum goes up to almost 0.5 ~ 0.6, which is higher than the train accuracy with SGD, almost 0.5. Validation accuraccies also show same trend. Validation accuracy with SGD momentum goes up to 0.5, which is higher than the validation accuracy with SGD, almost 0.45. Also, there are gaps between train accuracy and validate accuracy. Validate accuracies are lower than train accuracies in both optimizers.
2.(g) Adding L2 regularization (EECS 504 Only)
Add L2 regularization to the softmax classifier in 2(b)
2.(h) Training with L2 regularization (EECS 504 Only)
Train the model again using L2 regularization, using SGD
# initialize model (remember to set the l2 regularization weight > 0)
model_SGD_L2 = SoftmaxClassifier(hidden_dim = 300, weight_scale=1e-2, reg=0.01)
# start training using SGD. The training hyperparameter you choose should be same to the 4.2(c)
model_SGD_L2, train_acc_history_SGD_L2, val_acc_history_SGD_L2 = trainNetwork(
model_SGD_L2, train_data,
learning_rate = learning_rate_SGD,
lr_decay=lr_decay_SGD,
batch_size=batch_size_SGD,
num_epochs=10,
print_every=1000, optimizer = 'SGD')
(Iteration 1 / 4000) loss: 2.319169
(Epoch 0 / 10) train acc: 0.143000; val_acc: 0.132900
(Epoch 1 / 10) train acc: 0.445000; val_acc: 0.433300
(Epoch 2 / 10) train acc: 0.511000; val_acc: 0.462600
(Iteration 1001 / 4000) loss: 1.300620
(Epoch 3 / 10) train acc: 0.519000; val_acc: 0.470700
(Epoch 4 / 10) train acc: 0.503000; val_acc: 0.471100
(Epoch 5 / 10) train acc: 0.476000; val_acc: 0.471100
(Iteration 2001 / 4000) loss: 1.353539
(Epoch 6 / 10) train acc: 0.519000; val_acc: 0.471100
(Epoch 7 / 10) train acc: 0.532000; val_acc: 0.471100
(Iteration 3001 / 4000) loss: 1.495751
(Epoch 8 / 10) train acc: 0.518000; val_acc: 0.471100
(Epoch 9 / 10) train acc: 0.488000; val_acc: 0.471100
(Epoch 10 / 10) train acc: 0.510000; val_acc: 0.471100
# report test accuracy
acc = testNetwork(model_SGD_L2, data['X_test'], data['y_test'])
print("Test accuracy of model_SGD_L2: {}".format(acc))
Test accuracy of model_SGD_L2: 0.4762
2.(i) Plot
Using the train_acc_history and val_acc_history, plot the train & val accuracy versus epochs on one plot for model with and without L2 regularization, using SGD as optimizer.
#######################################################################
# TODO: Your Code here
#######################################################################
plt.plot(train_acc_history_SGD, label = "train accuracy using SGD")
plt.plot(val_acc_history_SGD, label = "validate accuracy using SGD")
plt.plot(train_acc_history_SGD_L2, label = "train accuracy using SGD and L2 regularization")
plt.plot(val_acc_history_SGD_L2, label = "validate accuracy using SGD and L2 regularization")
plt.xlabel("epochs")
plt.ylabel("accuracy")
plt.legend()
plt.plot()
#######################################################################
# END OF YOUR CODE #
#######################################################################
[]
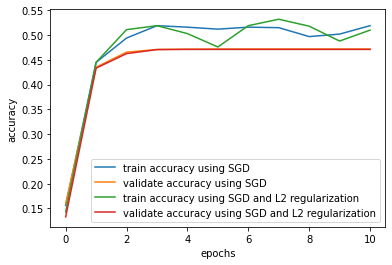
After adding L2 regularization, the gap between training accuracy and validation accuracy tends to decrease than before.
2.(j) Tune your own model
Feel free to tune any hyperparameters and choose any optimizer as you want – just train the best model you can!
#######################################################################
# TODO: Train your own model #
#######################################################################
# initialize model (set reg=0.0 for EECS 442 students)
your_model = SoftmaxClassifier(hidden_dim = 300, weight_scale = 1e-2, reg = 1e-2)
# train your moodel
your_model, train_acc_history_your_model, val_acc_history_your_model = trainNetwork(
your_model, train_data,
learning_rate = 0.05,
lr_decay= 0.5,
batch_size= 100,
num_epochs= 20,
print_every=1000, optimizer = "SGD_Momentum")
#######################################################################
# END OF YOUR CODE #
#######################################################################
(Iteration 1 / 8000) loss: 2.305209
(Epoch 0 / 20) train acc: 0.134000; val_acc: 0.123800
(Epoch 1 / 20) train acc: 0.541000; val_acc: 0.445000
(Epoch 2 / 20) train acc: 0.564000; val_acc: 0.491600
(Iteration 1001 / 8000) loss: 1.372331
(Epoch 3 / 20) train acc: 0.632000; val_acc: 0.500700
(Epoch 4 / 20) train acc: 0.621000; val_acc: 0.518600
(Epoch 5 / 20) train acc: 0.618000; val_acc: 0.524400
(Iteration 2001 / 8000) loss: 1.207773
(Epoch 6 / 20) train acc: 0.638000; val_acc: 0.525400
(Epoch 7 / 20) train acc: 0.671000; val_acc: 0.526500
(Iteration 3001 / 8000) loss: 1.141951
(Epoch 8 / 20) train acc: 0.637000; val_acc: 0.526500
(Epoch 9 / 20) train acc: 0.666000; val_acc: 0.529600
(Epoch 10 / 20) train acc: 0.666000; val_acc: 0.528600
(Iteration 4001 / 8000) loss: 0.943535
(Epoch 11 / 20) train acc: 0.641000; val_acc: 0.529600
(Epoch 12 / 20) train acc: 0.653000; val_acc: 0.528400
(Iteration 5001 / 8000) loss: 1.219422
(Epoch 13 / 20) train acc: 0.668000; val_acc: 0.528600
(Epoch 14 / 20) train acc: 0.659000; val_acc: 0.528600
(Epoch 15 / 20) train acc: 0.637000; val_acc: 0.528500
(Iteration 6001 / 8000) loss: 1.241045
(Epoch 16 / 20) train acc: 0.645000; val_acc: 0.528600
(Epoch 17 / 20) train acc: 0.651000; val_acc: 0.528600
(Iteration 7001 / 8000) loss: 1.226419
(Epoch 18 / 20) train acc: 0.663000; val_acc: 0.528600
(Epoch 19 / 20) train acc: 0.662000; val_acc: 0.528500
(Epoch 20 / 20) train acc: 0.647000; val_acc: 0.528500
# report test accuracy
# (Run this code only once when you obtain the highest model in validation set!)
acc = testNetwork(your_model, data['X_test'], data['y_test'])
print("Test accuracy of your model: {}".format(acc))
Test accuracy of your model: 0.5184